Eigenen GPT erstellen: Der umfassende technische Leitfaden von der Idee bis zum nachhaltigen Betrieb
Wenn Du einen eigenen GPT erstellen willst, musst Du zuerst klären, was „eigener GPT“ in Deinem Kontext bedeutet, welche Ziele Du verfolgst, welche Daten und Ressourcen vorhanden sind und wie Du Sicherheit, Compliance und Wirtschaftlichkeit sicherstellst. Dieser Leitfaden führt Dich systematisch durch Begriffe, Architektur, Datenstrategie, Training, Systemdesign, Sicherheit, Projektorganisation und Zukunftsperspektiven – mit konkreten Entscheidungen, Best Practices und Stolpersteinen, die Du vermeiden solltest.
1. Was „eigener GPT“ konkret bedeuten kann
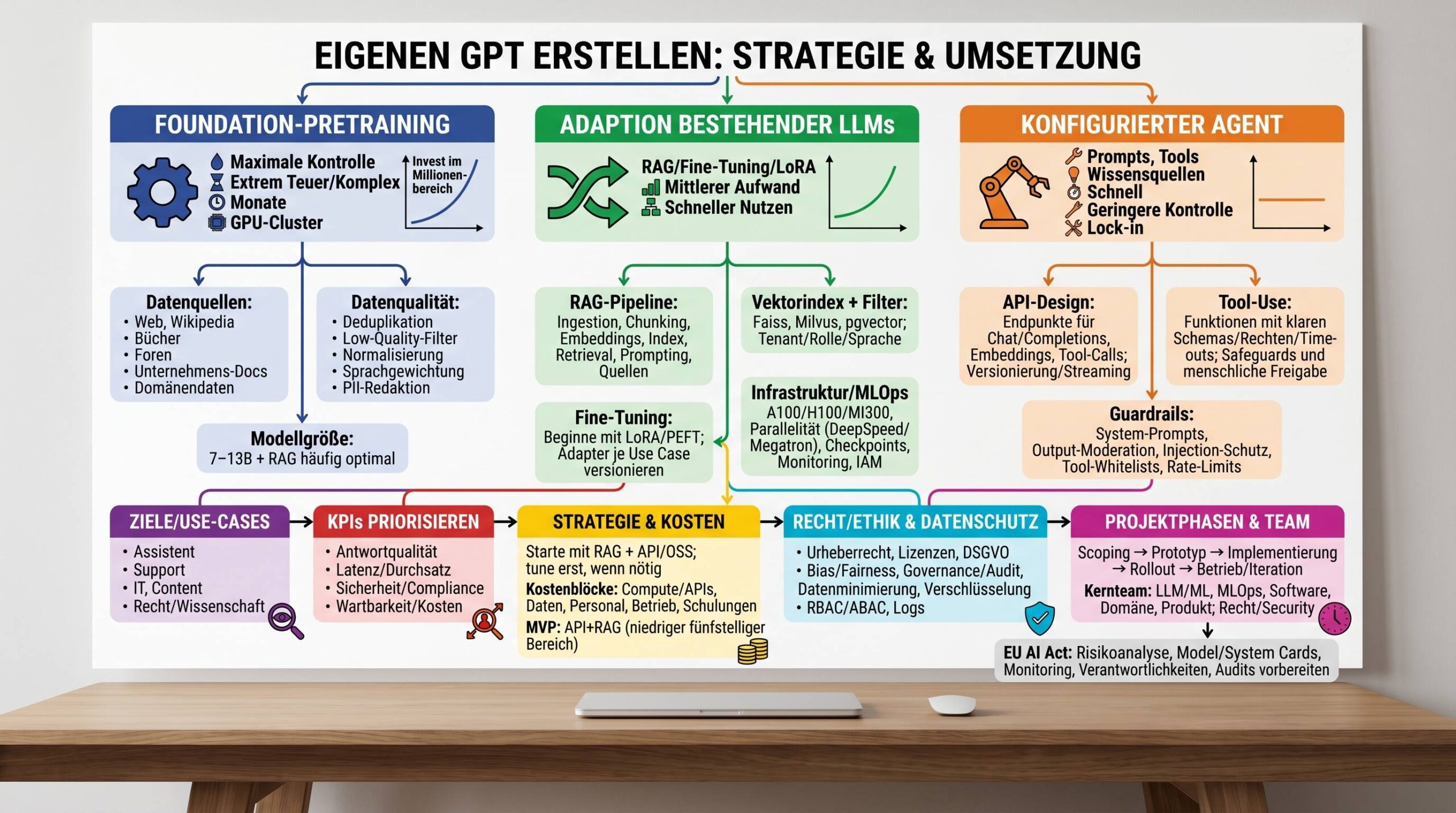
„Eigener GPT“ ist ein Schirmbegriff, der drei sehr unterschiedliche Ansätze umfasst. Entscheide zu Beginn, auf welcher Ebene Du agieren willst:
| Variante | Kurzbeschreibung | Aufwand | Vorteile | Risiken/Trade-offs | Typische Tools |
|---|---|---|---|---|---|
| Foundation-Model von Grund auf | Pretraining eines großen Decoder-only-Transformers auf Milliarden Tokens, optional Fine-Tuning | Sehr hoch (GPU-Cluster, Expertenteam, Monate) | Volle Kontrolle über Daten/Weights; maximale Unabhängigkeit | Millionenkosten, komplexe MLOps, hoher Zeit- und Personaleinsatz | Megatron/DeepSpeed, PyTorch, Ray, kubernetes, Slurm |
| Adaption eines bestehenden LLM | Open-Source- oder API-Modell mit Fine-Tuning/LoRA/RAG auf eigenen Daten | Mittel | Schneller Nutzen, gute Qualität, Kosten kontrollierbar | Abhängigkeit von Basismodell; Lizenz- und Hostingfragen | HuggingFace, LoRA/PEFT, LangChain/LlamaIndex, Vektorindizes |
| Konfigurierter Agent („Custom GPT“) | System-Prompts, Tools und Wissensquellen via Plattform konfigurieren | Niedrig | Schneller Start, Low-Code, ideal für Prototypen/FAQ | Geringere Tiefe/Kontrolle; Plattform-Lock-in | Plattform-Builder, RAG-Connectors, UI-Bausteine |
Merke: Lege früh fest, ob Du ein eigenes Modell trainierst, ein bestehendes Modell adaptierst oder einen Plattform-Agenten konfigurierst. Davon hängen Budget, Team, Zeitplan und Risiken unmittelbar ab.
2. Zielsetzungen und Qualitätskriterien schärfen
Formuliere präzise, was Dein System leisten soll und wie Du Erfolg misst. Typische Szenarien:
- Interner Assistent: Recherche, Dokumente, Codevorschläge – strikt auf interne Wissensquellen begrenzt.
- Kundensupport: First-Level-Antworten, Eskalation, CRM-Integration, stabile Guardrails gegen Halluzinationen.
- Engineering/IT: Log-/Telemetrieanalyse, Codeverständnis, lange Kontexte, formale Sprachen.
- Content & Marketing: Stil, Tonalität, Markenkonformität, Freigabeprozesse.
- Wissenschaft/juristische Arbeit: Struktur, Zitation, Nachvollziehbarkeit, Long-Context-Fähigkeit.
Priorisiere messbare Kriterien wie:
- Antwortqualität: Korrektheit, Vollständigkeit, Konsistenz über Turns.
- Latenz & Durchsatz: Interaktive Nutzung vs. Batch-Verarbeitung.
- Sicherheit/Compliance: Datenschutz, Bias/Toxicity, Guardrails, Auditierbarkeit.
- Wartbarkeit: Update-Zyklen von Wissen/Modell, Monitoring, Kostenkontrolle.

3. Ökonomie und strategische Trade-offs
Große Modelle selbst zu pretrainieren ist selten wirtschaftlich. In vielen Fällen liefern mittelgroße Open-Source-Modelle plus Retrieval-Augmented Generation (RAG) und gezieltes Fine-Tuning schnellere und robustere Ergebnisse. Kalkuliere:
- Initialkosten vs. Betriebskosten: GPU-Cluster/Cloud-Inferenz, Lizenzgebühren, API-Calls.
- Datenkosten: Beschaffung, Kuratierung, Annotation, rechtliche Klärungen.
- Personalkosten: ML/LLM, MLOps/DevOps, Domain-Expertise, Security/Compliance.
- Time-to-Value: Wie schnell generierst Du belastbaren Nutzen?
Pragmatische Faustregel: Starte mit Adaption (API/OSS) und RAG. Evaluiere Fine-Tuning erst, wenn RAG+Prompting Deine Zielmetrik nicht erreicht oder wenn Output-Stil/Kompaktwissen zentral ist.
4. Technische Grundlagen moderner GPT-Modelle
4.1 Transformer-Architektur in Kürze
- Decoder-only mit Masked Self-Attention (autoregressive Vorhersage: nächstes Token).
- Multi-Head Attention erfasst parallele Beziehungstypen im Kontext.
- Feedforward-Schichten, Residuals und LayerNorm stabilisieren und erhöhen Kapazität.
- Skalierung: Tiefe, Breite, Heads – Leistungsfähigkeit wächst mit Größe und Daten (unter Balancebedingungen).
4.2 Tokenisierung, Vokabular, Kontextfenster
- Tokenizer: BPE/Unigram subword-basiert; Vokabulargröße vs. Sequenzlänge abwägen.
- Kontextfenster: Von 2k bis 100k+ Tokens; längere Kontexte = höhere RAM/Latenz.
- Mehrsprachigkeit: Fairness des Tokenizers beachten, sonst ineffiziente Zerlegung.
4.3 Trainingsziel
Autoregressive Sprachmodellierung minimiert Kreuzentropie für P(x_t | x_1..x_{t-1}). Dieser einfache Lernauftrag führt zu implizitem Weltwissen, Grammatik und Mustererkennung – Grundlage für wenige-shot Generalisierung via Prompting. Ergänzend sind SFT (Supervised Fine-Tuning) und RLHF (Präferenzlernen) verbreitet.
4.4 Skalierungsgesetze
Kernidee: Performance verbessert sich systematisch mit Parametern, Datenmenge und Trainingsdauer – solange sie zueinander passen. Ein mittelgroßes Modell, gut trainiert und unterstützt durch RAG, schlägt oft ein größeres, schlecht trainiertes Modell im praktischen Einsatz.
5. Datenstrategie: Beschaffung, Aufbereitung, Recht
5.1 Datenquellen
- Pretraining-kontent: Web-Korpora, Wikipedia, Bücher, Foren, Tech-Dokumentation (Lizenz beachten).
- Unternehmensdaten: KB-Artikel, Tickets, Handbücher, Spezifikationen, E-Mails – ideal für SFT/RAG.
- Domänenspezifisch: Medizin, Recht, Finanzen: Publikationen, Normen, Gesetzestexte (Rechte klären!).
- Multimodal: Text+Bild/Tabellen/Code – komplexere Pipelines, potenziell hoher Mehrwert.
5.2 Bereinigung, Normalisierung, Filterung
- Deduplikation: Duplikate/Nahe-Duplikate entfernen, um Verzerrungen zu vermeiden.
- Low-Quality-Filter: Spam, maschinell generierte Seiten, Clickbait, sehr geringe Lesbarkeit.
- Normalisierung: Encoding-Fixes, Zeichensätze, Zeilenumbrüche, grundlegende Formatangleichung.
- Spracherkennung & Gewichtung: Relevante Sprachen priorisieren/filtern.
- PII-Schutz: Erkenne und entferne/pseudonymisiere personenbezogene Daten, wo möglich.
- Inhaltsfilter: Gewalt, Pornografie, Hassrede minimieren; später Guardrails ergänzen.
5.3 Annotierte Daten: SFT & RLHF
- SFT: Eingabe/Idealantwort-Paare für Dialog, QA, Tools. Klare Guidelines, Qualitätssicherung, Domänenreview.
- RLHF: Menschliche Präferenzrankings → Belohnungsmodell → RL-Optimierung; komplex, aber effektiv für Stil/Präferenz.
- Pragmatisch: Für viele Unternehmens-Use-Cases reichen RAG + sauberes Prompting + moderates SFT.
5.4 Recht & Ethik
- Urheberrecht/Lizenzen: AGB, TDM-Ausnahmen, kommerzielle Nutzung prüfen.
- Datenschutz (z. B. DSGVO): PII vermeiden, Datenflüsse dokumentieren, Betroffenenrechte respektieren.
- Bias & Fairness: Datenvielfalt beachten; regelmäßige Audits auf Verzerrungen.
- Governance: Richtlinien, Protokolle, Auditfähigkeit und Beschwerdemechanismen etablieren.

6. Modellierung & Training
6.1 Architekturentscheidungen
| Entscheidung | Optionen | Auswirkung | Hinweise |
|---|---|---|---|
| Modellgröße | 0.3B–3B, 7B–13B, 30B+ | Kapazität vs. Kosten/Latenz | Mittelgroße Modelle + RAG oft optimal für Unternehmen |
| Positionsembeddings | Absolute, Relative, Rotary (RoPE) | Generalisierung auf längere Kontexte | RoPE gängig bei Long-Context-Modellen |
| Präzision | FP16/BF16, INT8/INT4 (Inferenz) | Speicherbedarf, Stabilität | Training meist BF16; Inferenz quantisieren |
| Optimierer | AdamW, Adafactor | Konvergenz, Speicher | Bewährte Schedules: Warmup + Cosine-Annealing |
| Regularisierung | Dropout, Weight Decay | Überanpassung, Stabilität | Besonders bei kleinem SFT-Datensatz wichtig |
6.2 Infrastruktur & verteiltes Training
- Hardware: GPUs mit hohem HBM (A100/H100/MI300), schneller Interconnect (NVLink/Infiniband).
- Parallelität: Daten-, Modell-, Pipeline-Parallelität; hybride Strategien via DeepSpeed/Megatron.
- MLOps: Checkpoints, Reproduzierbarkeit, Monitoring (Loss, Gradienten, GPU-Util), Konfig-Management.
- Sicherheit: Verschlüsselung, VPC/On-Prem bei sensiblen Daten, Rollenbasiertes IAM.
6.3 Trainingsablauf & Stabilität
- Initialisierung: Geeignete Init-Schemata für Transformer (z. B. Xavier-variante).
- Tokenisierung: Sequenzierung, Batch-Building, ggf. Curriculum/Shard-Strategie.
- Lernraten-Schedule: Warmup → Plateau → Decay (z. B. Cosine); zu hoch = Divergenz, zu niedrig = ineffizient.
- Checkpoints: Regelmäßig sichern (Weights, Optimizer-States, Configs); Wiederaufnahme ermöglichen.
- Validierung: Held-out-Loss, domänenspezifische Proben; Frühwarnung bei Overfitting/Instabilität.
6.4 Fine-Tuning & Parameter-effiziente Methoden
- Vollständiges Fine-Tuning: Hoher Speicherbedarf, Risiko von Catastrophic Forgetting.
- LoRA/PEFT/Adapter: Zusätzliche Low-Rank/Adapter-Parameter; Basismodell einfrieren, effizient, modular.
- Prefix/P-Tuning: Trainierbare Prompts/Prefixe; leichtgewichtig, gute Stil-/Aufgabenkontrolle.
- Best Practice: Starte mit LoRA. Halte mehrere Adapter pro Use Case vor und versioniere sie.
6.5 Evaluierung & Qualitätsmetriken
- Allgemeine Benchmarks: Sprachverständnis, Logik, Mathe, Coding – nur Anhaltspunkte.
- Domänentests: Realistische Tickets, Dokumente, interne Fragen; „goldene“ Referenzantworten.
- Qualitativ: Review durch Fachexperten auf Korrektheit, Klarheit, Stil, Quellenangaben.
- Risiken: Toxicity, Bias, Sicherheit; definierte No-Go-Kategorien testen.
| Metrik | Beschreibung | Einsatz |
|---|---|---|
| Perplexity/Validierungs-Loss | Statistische Güte der Sprachmodellierung | Training/Pretraining-Fortschritt |
| Task-Accuracy/F1 | Trefferquote auf domänenspezifischen Aufgaben | Praktische Tauglichkeit |
| Antwortlatenz/P95 | Performance in Interaktion | User Experience/SLAs |
| Toxicity/Bias-Scores | Inhaltliche Sicherheit und Fairness | Compliance/Guardrails |
7. Systemarchitektur: Vom Modell zur produktiven Anwendung
7.1 API-Design & Inferenz
- Endpunkte: Chat/Completion, Embeddings, Tool-Calls; saubere Schemas und Versionierung.
- Skalierung: Load-Balancer, horizontale Replikation, Caching, Token-Streaming.
- Optimierung: Quantisierung, Distillation, Prompt-Cache, Kontextkompression.
- Deployment-Modelle: On-Prem/VPC bei sensiblen Daten; API-Provider für schnellen Start.
7.2 Retrieval-Augmented Generation (RAG)
- Ingestion: Dokumente in Abschnitte teilen, Embeddings generieren, Metadaten anreichern.
- Indexing: Vektorindex (z. B. Faiss, Milvus, pgvector) + Filter (Mandant, Rolle, Sprache).
- Retrieval: Semantische Suche, ggf. Re-Ranking; Top-K/Maximal Marginal Relevance.
- Prompt-Konstruktion: Frage + relevante Passagen + Richtlinien → an LLM.
- Antwort mit Quellen: Zitate/URLs/IDs ausliefern; Ketten-of-Thought nur intern loggen.
Vorteil von RAG: Aktualisierbares Wissen, bessere Nachvollziehbarkeit, geringerer Fine-Tuning-Bedarf. Oft der größte Hebel, wenn Du Deinen eigenen GPT erstellen und produktionsreif machen willst.
7.3 Tool-Orchestrierung & Funktionsaufrufe
- Funktionen definieren: Formale Signaturen (Eingaben/Ausgaben), Rollenrechte, Zeitlimits.
- Auslösung durch das LLM: Das Modell wählt situativ Tools (z. B. CRM-Query, Kalkulation, Web-Scraper).
- Safeguards: Parameter-Validierung, Rate-Limits, Scoping, menschliche Freigabe bei kritischen Aktionen.
Beispiel: Funktion „getOrderStatus(orderId: string) → {status, eta, lastUpdate}“; das Modell ruft sie bei passenden Anfragen auf und integriert die Antwort in die Kommunikation.
7.4 UX & Interaktion
- Kontextklarheit: Beispielanfragen, Fähigkeiten/Grenzen sichtbar machen, Rollenbeschreibungen.
- Fehlerbehandlung: Rückfragen, Quellen anzeigen, Eskalation an Menschen.
- Einbettung in Workflows: IDE-Plug-ins, CRM-Widgets, Editorsidebars – weniger „Chat“, mehr „Assistenz im Kontext“.
- Unsicherheitskommunikation: Qualitative Hinweise, Konfidenz-Proxies, „Bitte prüfen“-Indikatoren.
8. Sicherheit, Governance, Qualitätssicherung
8.1 Risiken & Bedrohungen
- Halluzinationen: Falsche/scheinpräzise Antworten.
- Missbrauch: Phishing-Texte, Fake-News, Schadcode.
- Prompt-Injection: Externe Inhalte manipulieren Systemanweisungen.
- Datenabfluss: Sensible Inhalte in Prompts/Logs/Antworten.
- DoS & Zugriff: Lastspitzen, unautorisierte Nutzung, Schwachstellen in Tool-Calls.
8.2 Guardrails & Moderation
- System-Prompts: Klare Verbote/Erlaubnisse, Eskalationsregeln.
- Output-Filter: Toxicity/Hate/NSFW-Classifier, PII-Redaktion.
- Prompt-Sicherheit: Kontextisolation, Content-Sanitization, Deserialisierungsschutz.
- Policy-Framework: Themenrestriktionen, Tool-Whitelists, Rate-Limits.
- Manuelle Moderation: Review-Queues für Grenzfälle, Missbrauchsanalyse.
8.3 Datenschutz, Zugriff, Logging
- Minimierung: Nur notwendige Daten verarbeiten; Pseudonymisierung, Maskierung.
- Transport/Ruhe: Ende-zu-Ende-Verschlüsselung, Secrets-Management, HSM wo nötig.
- RBAC/ABAC: Rollen-/Attributbasierte Zugriffe, getrennte Tenant-Kontexte.
- Audit-Logs: Anfragen, Antworten, Tool-Calls; DSGVO-konforme Aufbewahrung/Löschung.
8.4 Governance & Verantwortung
- Interdisziplinäres Gremium: IT/ML, Fachbereiche, Recht/Compliance, Security, Betriebsrat (wo relevant).
- Prozesse: Freigaben, Change-Management, Incident-Response, regelmäßige Risiko-Reviews.
- Transparenz: Model/System Cards, Datenherkunft, Grenzen/Haftungshinweise.
9. Praktische Wege zu einem „eigenen GPT“ ohne Pretraining
| Ansatz | Startaufwand | Datenhoheit | Kontrolle | Performance | Typische Nutzung |
|---|---|---|---|---|---|
| API-basiertes Foundation Model | Niedrig | Mittel (abhängig von Anbieter-Optionen) | Mittel | Hoch (State-of-the-Art) | Schnelle MVPs, variable Lasten, geringe ML-Last im Team |
| Open-Source-Modell hosten | Mittel | Hoch (On-Prem/VPC möglich) | Hoch | Mittel–hoch (modellabhängig) | Datenkritische Anwendungen, maßgeschneiderte Anpassung |
| Low-Code/Custom-GPT-Builder | Sehr niedrig | Niedrig–Mittel | Niedrig–Mittel | Ausreichend–gut | FAQ-Bots, Team-Assistenten, schnelle Pilotierung |
Empfehlung: Kombiniere die Ansätze in einer mehrschichtigen Strategie: zentrale, sensible Workloads auf eigenem OSS-Host; flexible Use Cases über APIs; Exploratives via Low-Code – alles eingebettet in gemeinsame RAG-, Logging- und Auth-Komponenten.
10. Projektplanung, Team & Betrieb
10.1 Phasen
- Anforderung & Scoping: Ziele, Nutzer, Datenlagen, rechtliche Rahmenbedingungen.
- Prototyping: Prompting, RAG, UI-Skizzen; früh Feedback einholen.
- Implementierung: Datenpipelines, Guardrails, APIs, Monitoring, Tests.
- Rollout: Schulungen, Change-Management, Integration in Prozesse.
- Betrieb & Weiterentwicklung: KPIs tracken, Daten/Modelle aktualisieren, Iterationen planen.
10.2 Rollen & Kompetenzen
- LLM/ML-Engineers: Modellwahl, Fine-Tuning, Evaluierung.
- MLOps/DevOps: Infrastruktur, Deployments, Skalierung, Observability.
- Software Engineers: API, UI, Tool-Use, Integrationen.
- Domänenexpertinnen: Datenkuratierung, Review, Akzeptanz.
- Produkt/Projekt: Priorisierung, Roadmap, Stakeholdermanagement.
- Recht/Compliance/Security: Datenschutz, Lizenzen, Audits, Policies.
- UX/Tech Writing: Interaktionsdesign, Hilfetexte, Onboarding.
10.3 Budget, Zeit, Erfolg
- Kostenblöcke: Compute/Storage/Netz, APIs/Lizenzen, Daten/Annotation, Personal, Schulungen.
- Zeitbedarf: MVPs mit API+RAG in Wochen; tief integrierte Systeme in Monaten.
- Erfolgskriterien: Technisch (Qualität/Latenz/Fehler), Geschäftlich (Zeitersparnis, NPS, Durchsatz, Kostenreduktion).
10.4 Change-Management
- Kommunikation: Ziele, Grenzen, Rollen – transparent und konkret.
- Training: Praxisnahe Schulungen, Prompting-Guides, Best Practices.
- Beteiligung: Nutzer früh in Prototypen einbeziehen; Feedback-Loops fest verankern.
- Akzeptanz: Zuverlässige Kernfunktionen zuerst; schrittweise ausbauen.
Praxis-Tipp: Definiere ein Minimum Viable Workflow (MVW) – den kleinsten, stabilen End-to-End-Prozess mit klar messbarem Nutzen – bevor Du weitere Features anhängst.
11. Zukunftsperspektiven
11.1 Multimodalität
Text+Bild/Audio/Video eröffnen neue Szenarien (z. B. Dokumente plus Diagramme/Fotos). Der Mehrwert ist groß, die Pipeline-Komplexität ebenfalls. Plane modular, damit Du später multimodale Bausteine ergänzen kannst.
11.2 Personalisierung
Rollenspezifische Profile, Präferenzen, adaptive Detaillierung – alles möglich, aber datenschutzsensibel. Transparente Steuerung, Opt-out-Möglichkeiten und Bias-Kontrollen sind Pflicht.
11.3 Agentenzusammenarbeit & Human-in-the-Loop
Mehrere spezialisierte Agenten (Recherche, Planung, Stil) können kooperieren und sich gegenseitig prüfen. In regulierten Bereichen bleibt die menschliche Freigabe essenziell – designe Deine Workflows dafür.
11.4 Regulierung & Standardisierung
Bereite Dich auf strengere Anforderungen vor (z. B. EU AI Act): Risikoanalysen, Dokumentation (Model/System Cards), Monitoring, Auditierbarkeit. Die frühzeitige Etablierung sauberer Prozesse zahlt sich aus.
Fazit
Einen eigenen GPT erstellen heißt weit mehr, als ein Modell zu starten: Es ist ein End-to-End-Vorhaben aus klarer Zieldefinition, belastbarer Datenstrategie, solider Architektur (API, RAG, Tool-Use), konsequenter Sicherheit/Compliance, sauberer Evaluierung und gelebtem Betriebs- und Change-Management. Für die meisten Anwendungsfälle ist die Adaption bestehender Modelle – kombiniert mit Retrieval-Augmented Generation und parameter-effizientem Fine-Tuning – der wirtschaftlich sinnvollste Weg. So erzielst Du rasch messbaren Nutzen, bleibst flexibel und behältst die Kontrolle über Deine Daten. Starte iterativ, dokumentiere Entscheidungen, etabliere Guardrails, messe echte Geschäftsmetriken und erweitere die Fähigkeiten Deines Systems Schritt für Schritt. Wer diesen Weg konsequent und verantwortungsvoll geht, schafft sich einen nachhaltigen Vorteil im produktiven Einsatz generativer KI.
FAQ
Wie starte ich am schnellsten, wenn ich einen eigenen GPT erstellen will?
Beginne mit einem API-basierten Modell plus RAG auf Deinen Dokumenten. Baue ein Minimal-UI, definiere 5–10 repräsentative Testfälle, messe Antwortqualität und Latenz. Erst bei Bedarf LoRA/SFT ergänzen.
Was kostet das ungefähr?
Hängt stark vom Umfang ab. Ein MVP mit API+RAG kann im niedrigen fünfstelligen Bereich (inkl. Arbeitszeit) starten. Eigenes Hosting eines mittelgroßen OSS-Modells erfordert dedizierte GPU-Ressourcen (mehrere Tausend Euro/Monat). Pretraining großer Modelle geht in den Millionenbereich.
Wann brauche ich Fine-Tuning statt nur RAG?
Wenn der gewünschte Stil/Verhalten sehr spezifisch ist, wenn Du Tool-Use-Robustheit verbessern willst oder wenn RAG trotz guter Indizes die Zielqualität nicht erreicht. Ansonsten liefert RAG oft schneller den größten Hebel.
Wie verhindere ich Halluzinationen?
- Nutz RAG mit relevanten, aktuellen Quellen.
- Zeige Zitate/Quellen an und ermutige zur Verifikation.
- Implementiere Guardrails (No-Go-Themen, Confidence-Checks).
- Setze Human-in-the-Loop für kritische Outputs ein.
On-Premises oder Cloud?
Bei strengen Datenschutz-/Compliance-Anforderungen ist On-Prem/VPC sinnvoll. Für schnelle Prototypen und variable Last sind Cloud/APIs effizient. Mischformen sind häufig: sensible Workloads intern, restliche extern.
Ist RLHF nötig?
Nicht zwingend im Unternehmenskontext. Oft reicht SFT auf kuratierten Interaktionen plus klare Policies. RLHF lohnt sich, wenn Du stark nutzerpräferenzgetriebene Antworten im großen Stil liefern willst.
Welche Modellgröße ist sinnvoll?
Für viele Use Cases reichen 7–13B-Modelle, kombiniert mit RAG. Größere Modelle bringen Mehrleistung, erhöhen aber Kosten/Latenz. Miss an Deinen Domänenaufgaben, nicht nur an generischen Benchmarks.
Wie messe ich ROI?
Definiere vorab Prozessmetriken: Bearbeitungszeit, Erstlösungsquote, Eskalationsrate, Nutzerzufriedenheit, Ticketdurchsatz, Dokumentationsqualität. Vergleiche „vorher–nachher“ über definierte Zeiträume.
Wie gehe ich mit DSGVO um?
Minimiere verarbeitete PII, setze Pseudonymisierung/Maskierung ein, führe Verarbeitungsverzeichnisse, implementiere RBAC/ABAC, sichere Übertragung/Speicherung, beachte Datenresidenz und Aufbewahrungsfristen. Binde Recht/DSB früh ein.
Welche Rollen brauche ich mindestens im Team?
Ein Kernteam aus LLM/ML-Engineer, MLOps/DevOps, Software Engineer, Domänenexpertin und einer Person für Produkt/Projekt. Ergänze Recht/Compliance und Security je nach Risiko.
Wie oft sollte ich Daten und Wissensquellen aktualisieren?
Für RAG: so oft wie sich Inhalte ändern (täglich/wöchentlich), mit automatisierten Ingestion-Pipelines. Für SFT/Adapter: quartalsweise oder nach signifikanten Prozess-/Policy-Änderungen.
Welche Guardrails sind Pflicht?
System-Prompts mit klaren Verboten/Erlaubnissen, Output-Moderation (Toxicity/PII), Prompt-Schutz (Injection-Resistenz), Tool-Whitelists und Audit-Logs. In kritischen Flows: menschliche Freigabe.
Wie gehe ich mit dem EU AI Act um?
Erstelle Risikoanalysen, führe Dokumentation (Model/System Cards), etabliere Monitoring/Logging, plane Audits, definiere Verantwortlichkeiten. Halte Dich an Transparenzpflichten und bereite Prozesse für Konformitätsbewertungen vor.