Duck AI: Architektur, Funktionen, Sicherheit und Governance – dein praxisnaher Leitfaden
Hinweis vorab: „Duck AI“ ist aktuell kein weltweit eindeutig abgegrenztes Produkt, sondern ein Name, der in unterschiedlichen Kontexten für verschiedene KI-Lösungen stehen kann. In diesem Leitfaden nutzt du „Duck AI“ als realistisch konzipiertes Referenzsystem, um moderne KI-Plattformen strukturiert zu verstehen, zu bewerten und einzusetzen.
Was „Duck AI“ im Kern meint
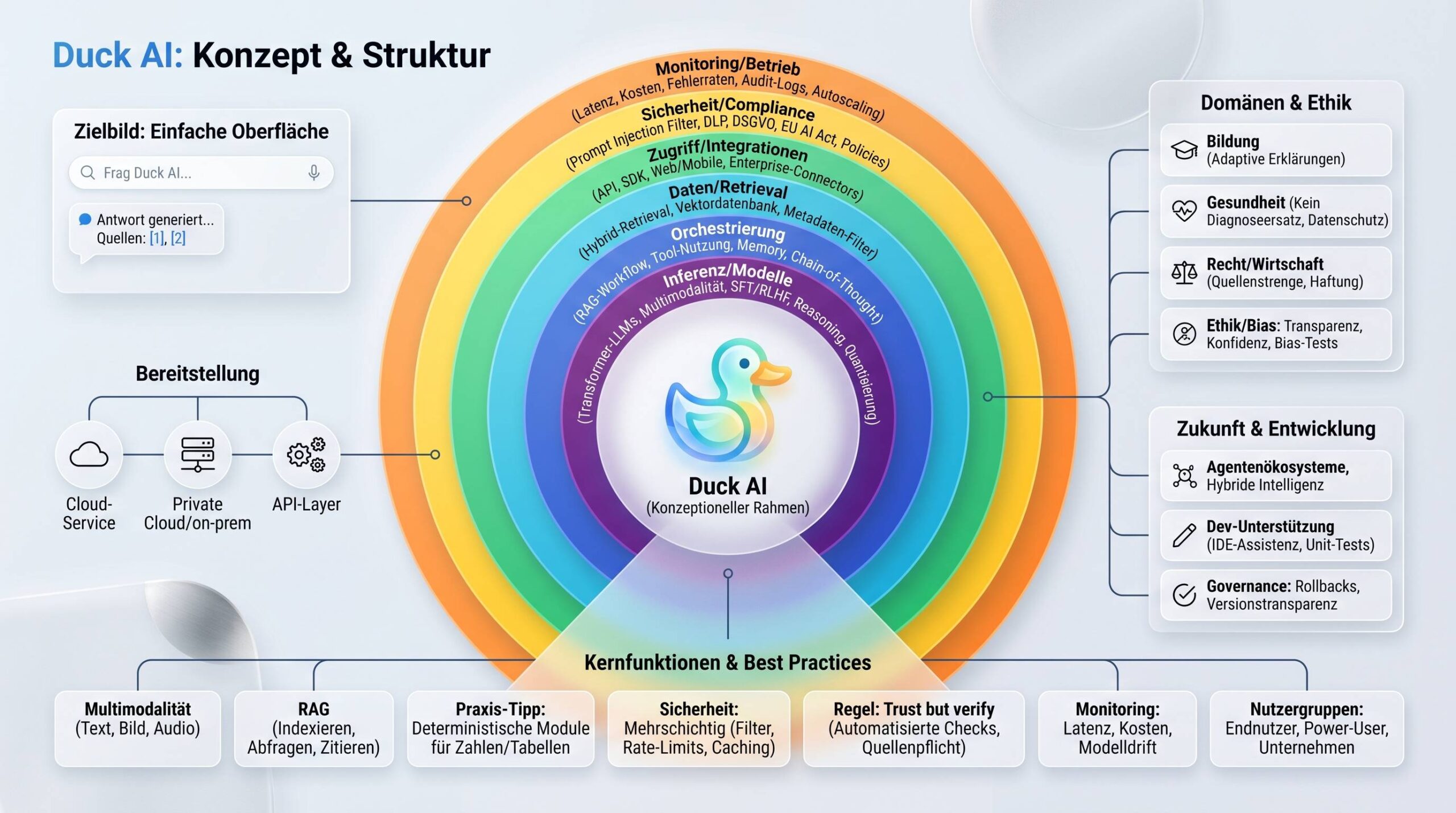
Unter „Duck AI“ verstehst du ein mehrzweckfähiges KI-System, das große Sprachmodelle (LLMs), multimodale Verarbeitung (Text, Bild, ggf. Audio), Retrieval-Augmented Generation (RAG), Orchestrierungsschichten, Sicherheitsmechanismen und Integrations-APIs zu einer nutzerfreundlichen Plattform vereint. Es kann als Cloud-Dienst, als API-Layer über bestehenden Foundation Models oder als Enterprise-Instanz (private Cloud, on-premises) betrieben werden.
Die Positionierung ist bewusst niedrigschwellig: einfache Bedienung, klar strukturierte Schnittstellen, dabei ausreichend Tiefe für Entwicklerteams, Data-Science-Abteilungen und regulierte Branchen. In der Praxis bedeutet das: Du erhältst eine einheitliche Chat-/Aufgabenoberfläche, während im Hintergrund spezialisierte Komponenten (Modelle, Tools, Retrieval) orchestriert werden.
Kernarchitektur auf einen Blick
Die Architektur teilt sich in wohldefinierte Schichten, die Skalierbarkeit, Sicherheit und Erweiterbarkeit gewährleisten.
| Schicht | Aufgabe | Typische Komponenten |
|---|---|---|
| Inferenz & Modelle | Ausführung der KI-Modelle bei Anfragen | LLMs (Transformer), multimodale Encoder/Decoder, Quantisierung, Sharding |
| Orchestrierung | Routing, Tool-Aufrufe, Kontextverwaltung | Task-Classifier, Tool-Executors, RAG-Pipeline, Memory/Conversation-State |
| Daten & Retrieval | Kontextrecherche und -anreicherung | Vektorindizes, Dokumentenspeicher, Konnektoren, Embedding-Modelle |
| Zugriff & Integrationen | Interaktion mit Nutzenden und Systemen | Web-UI, mobile Apps, REST/GraphQL-APIs, SDKs, IDE-Plugins |
| Sicherheit & Compliance | Schutz, Prüf- und Nachweismechanismen | Prompt-Filter, Policy-Engines, Rate-Limits, Audit-Logs, Verschlüsselung |
| Monitoring & Betrieb | Qualität, Stabilität, Kostenkontrolle | Tracing, Metriken (Latenz/Fehler), Canary-Releases, Autoscaling |
Wichtige Architekturmerkmale
- Transformer-basierte LLMs bilden den Kern für Sprachverständnis und -generierung.
- Multimodalität erlaubt dir, Text, Bilder (z. B. Screenshots) und ggf. Audio gemeinsam zu verarbeiten.
- RAG verbindet Modellkompetenz mit aktuellen, externen Wissensquellen.
- Tool-Nutzung (z. B. Rechenmodule, Code-Ausführung, Datenbankabfragen) erhöht Verlässlichkeit bei Fakten und Zahlen.
- Memory & Kontextmanagement sorgen dafür, dass längere Dialoge konsistent bleiben.

Modelllandschaft und Algorithmen
In „Duck AI“ dominieren große Sprachmodelle auf Basis von Self-Attention. Sie sind in der Regel durch Supervised Fine-Tuning (SFT) und Reinforcement Learning from Human Feedback (RLHF) auf hilfreiches, sicheres Verhalten ausgerichtet. Hinzu kommen:
- Multimodale Modelle, die Bild-Encoder (z. B. Vision Transformer) mit Sprach-Decodern kombinieren.
- Retrieval-Module, die über Embeddings semantisch passende Dokumente liefern.
- Reasoning-Strategien wie Chain-of-Thought (explizites Denken) oder Tool-gestütztes Rechnen.
- Optimierungen für Inferenz (Quantisierung, Tensor-Parallelismus, sparsity), um Kosten und Latenz zu senken.
Bei tabellarischen oder numerischen Aufgaben setzt du bevorzugt auf deterministische Hilfsfunktionen (z. B. Python-Rechenkern), statt die LLM-Approximation unkontrolliert rechnen zu lassen. So steigerst du Präzision und Revisionssicherheit.
Sicherheit und Zuverlässigkeit – Schicht für Schicht
Ein robustes System schützt sich nicht an einer Stelle, sondern auf mehreren Ebenen zugleich. Im Folgenden findest du typische Bedrohungen und Gegenmaßnahmen.
| Risiko | Beispiel | Gegenmaßnahmen |
|---|---|---|
| Prompt Injection | Dokumente oder Nutzerinputs versuchen, Sicherheitsanweisungen zu überschreiben. | Input-Sanitization, Content-Scoring, strikte Systemprompts, Context-Segregation, Tool-Permissions |
| Jailbreaking | Erzwingen von Antworten außerhalb der Richtlinien. | Red-Teaming, Adversarial Training, Policy-Filter, Output-Moderation |
| Datenexfiltration | Anfordern von geheimen Trainings- oder Kundendaten. | Data Loss Prevention (DLP), Response-Redaction, Zugriffstrennung, Null-Data-Prompts |
| Halluzinationen | Falschinformationen mit scheinbarer Sicherheit. | RAG, Quellenzitierung, Abstufung der Sicherheitstonalität, „Don’t know“-Fallbacks |
| Denial-of-Service | Anfragenfluten, die Systeme überlasten. | Rate-Limits, Token-Budgets, Caching, Autoscaling, Priorisierung |
Praxisregel: „Trust but verify.“ Verlange von produktiven Antworten bei kritischen Themen Quellen, nutze automatisierte Checks (z. B. Faktenabgleich) und definiere klare Abbruchkriterien, wenn Unsicherheit zu hoch ist.
- Monitoring: Tracke Latenz, Fehlerraten, Abbruchhäufigkeiten, Moderations-Treffer, Modelldrift, Kosten pro Anfrage.
- Feedback-Schleifen: Ermögliche Nutzerbewertungen, Flagging und Rückmeldungen mit schnellem Weg zurück in das Tuning oder die Orchestrierung.
- Auditierbarkeit: Sichere Protokolle (pseudonymisiert), reproduzierbare Prompts, Modell- und Datenversionen.
Nutzergruppen und Zugangswege
Ein universelles System dient heterogenen Zielen – vom Casual-User bis zur Enterprise-IT. Unterschiedliche Gruppen benötigen unterschiedlich tiefe Kontrolle.
| Nutzergruppe | Primärer Zugang | Erwartungen |
|---|---|---|
| Endnutzende | Web-Chat, Mobile-App | Einfache Bedienung, sichere Antworten, mehrsprachige Unterstützung |
| Power-User & Data Scientists | APIs, SDKs, CLI | Konfigurierbarkeit, Beispiele, Reproduzierbarkeit, Logging |
| Unternehmen/Organisationen | Private Cloud, on-prem, SSO-Integration | Skalierung, Compliance, Governance, granulare Rechte |

Konversation und Prompt-Design
Die Qualität deiner Ergebnisse hängt stark von der Gestaltung der Interaktion ab – sowohl intern (Systemprompts) als auch extern (Benutzereingaben).
- Rollen-Definition: Lege fest, ob der Agent als Experte, Prüfer oder Ideengeber agiert; passe Tonalität und Detaillierung an.
- Kontextökonomie: Nutze Zusammenfassungen, memories und semantisches Chunking, um relevante Historie im Kontextfenster zu halten.
- Aktive Klärung: Fordere Rückfragen ein, wenn Spezifikationen unklar sind, statt riskante Annahmen zu treffen.
- Output-Steuerung: Definiere Ziel-Formate (bullet points, JSON, Tabellen) und Qualitätskriterien (Quellen, Umfang, Stil).
Wissensarbeit mit RAG: präzise Antworten statt Halluzinationen
Retrieval-Augmented Generation verbindet freie Textgenerierung mit der punktgenauen Integration externer Quellen.
- Indexierung: Zerlege Dokumente (PDF, HTML, E-Mails) in semantische Chunks, erstelle Embeddings und speichere sie in einem Vektorindex.
- Abfrage: Wandle Fragen in Embeddings um, hole die relevantesten Passagen (Top-k) ab.
- Kontextaufbereitung: Relevante Stücke werden dedupliziert, sortiert, ggf. zitiert und in den Prompt injiziert.
- Generierung: Das Modell antwortet auf Basis des Kontextes; idealerweise mit Zitaten/Belegen.
- Validierung: Automatisierte Heuristiken (z. B. Quellenabdeckung, Widerspruchsprüfung) erhöhen Verlässlichkeit.
- Best Practices:
- Nutze Hybrid-Retrieval (BM25 + Vektor) für höhere Trefferqualität.
- Optimiere Chunk-Größe und Überschneidung (overlap) pro Dokumententyp.
- Füge Metadaten (Datum, Quelle, Autor) hinzu und ermögliche Filter.
- Erzwinge bei kritischen Antworten Quellenzitate und weise Unsicherheit explizit aus.
Entwicklerunterstützung und Code-Generierung
Als Code-Assistent ist „Duck AI“ besonders wertvoll, wenn es Syntax, Semantik und Projektkontext verbindet.
- Inline-Hilfen in IDEs: Vervollständigungen, Refactorings, Dokumentationsvorschläge.
- Fehlersuche: Erkläre Fehlermeldungen, schlage Fixes vor, verweise auf relevante Tickets/Docs.
- Testgetriebene KI: Erzeuge Unit-Tests für generierten Code; führe sie automatisiert aus (Tool-Aufrufe).
- Projektkontext: Lerne interne Konventionen, Bibliotheken, Architekturentscheidungen – mit strengen Datenschutzregeln.
- Policy-Checks: Erzwinge Lizenz- und Sicherheitsvorgaben (z. B. Verbotslisten für unsichere Patterns).
Wichtig: Code, der automatisch entsteht, bleibt reviewpflichtig. Automatisierte Tests, SAST/DAST und Code-Reviews sind integrale Teile eines sicheren Workflows.
Spezialisierte Domänenfunktionen
Bildung
- Adaptive Erklärungen auf unterschiedlichen Niveaus, Beispiele, Übungsaufgaben.
- Didaktisch sinnvolle Progression (vom Konkreten zum Abstrakten).
- Prävention von „Lernen ohne Verstehen“: Erklären statt nur Lösungen ausgeben.
Gesundheit
- Laienverständliche Aufbereitung von Leitlinien, Gesprächsvorbereitung.
- Strikte Hinweispflicht: kein Ersatz für medizinische Diagnose oder Therapieentscheidungen.
- Hohe Anforderungen an Datenschutz und Auditierbarkeit.
Recht & Wirtschaft
- Vertragsanalyse, Compliance-Screening, Risikohinweise, Szenarioanalysen.
- Stringente Quellenarbeit und Unsicherheitskommunikation; Vermeidung trügerischer Exaktheit.
- Konsequente Trennung sensibler Daten und Klärung von Haftungsfragen.
Datenschutz, Sicherheit und DSGVO
Gerade in Europa ist Datenschutz ein zentrales Kaufkriterium. Achte auf klare, konfigurierbare Modi.
| Einstellung/Modus | Wirkung | Worauf du achten solltest |
|---|---|---|
| Training-Opt-out | Nutzereingaben fließen nicht in Modellverbesserung ein. | Vertraglich zusichern lassen, technisch überprüfbar (Audit). |
| Regionale Datenverarbeitung | Daten bleiben in festgelegten Rechtsräumen (z. B. EU/EWR). | Datenresidenz-Optionen, Zertifizierungen der Rechenzentren. |
| On-Prem/Private Cloud | Volle Kontrolle, keine Datenabflüsse in öffentliche Dienste. | Wartungsaufwand, Hardwarekapazitäten, Updatemechanismen. |
| Verschlüsselung | In Transit (TLS) und at Rest (AES-256 o. ä.). | Schlüsselmanagement, HSM, Rotation, Zugangsbeschränkungen. |
| Logging/Monitoring | Pseudonymisierte Protokolle, minimal nötige Daten. | Löschkonzepte, Aufbewahrungsfristen, Zugriffskontrollen. |
- DSGVO-Elemente: Auskunftsrechte, Datenlöschung, Zweckbindung, Auftragsverarbeitung (DPA), Privacy by Design/Default.
- Compliance: Klare Nutzungsbedingungen, Transfer Impact Assessments, unabhängige Audits, Zertifizierungen.
Ethik, Bias und Fairness
KI-Modelle spiegeln Trainingsdaten – inklusive Verzerrungen. Du brauchst Verfahren, um Risiken zu erkennen und zu mindern.
- Bias-Tests: Standardisierte Evaluationssets für sensible Gruppen und riskante Themen.
- Adversarial Testing: Probe auf stereotype, diskriminierende und manipulative Anfragen.
- Richtlinienkommunikation: Klare Hinweise, wo das System zuverlässig ist – und wo nicht.
- Transparenz: Erklärbare Antworten, Konfidenzhinweise, Quellenangaben, Dokumentation der Grenzen.
Governance, Versionierung und Verantwortlichkeiten
- Modell-Governance: Definiere, wer Modellupdates freigibt, wie Risiken bewertet und Rollbacks gehandhabt werden.
- Versionstransparenz: Zeige die aktive Modellversion, Changelogs und Migrationshinweise.
- Vorfallmanagement: Meldewege, Reaktionspläne, Lessons Learned – dokumentiert und überprüfbar.
- Regulatorik: Richte dich an entstehende Rahmenwerke (z. B. EU AI Act) aus; kategorisiere Risiken und Pflichten.
Betrieb, Skalierung und Kostenkontrolle
- Autoscaling: Skaliere GPU/TPU-Cluster bedarfsgerecht; nutze Queueing und Priorisierung.
- Kostenhebel: Quantisierung, kleinere spezialisierte Modelle für einfache Tasks, Caching, Prompt-Optimierung.
- Routing: Wähle dynamisch zwischen Modellen (z. B. „smart routing“ nach Aufgabentyp/Komplexität).
- Performance: Token-Streaming, frühzeitige Abbrüche bei irrelevanten Outputs, Speicherlokalität.
Entwicklungszyklen und Qualitätsmetriken
Statt großer, seltener Releases profitierst du von iterativen Zyklen und klaren Metriken.
- Kontinuierliche Verbesserung: Sammle Fehlermuster, Nutzerfeedback, Moderationshits und verarbeite sie im Fine-Tuning.
- Evaluationsmetriken:
- Qualität: Hilfreichkeits-Score, Korrektheits-Rate, Quellenabdeckung.
- Sicherheit: Toxicity, Jailbreak-Resistenz, DLP-Trefferquote.
- Technik: Latenz (P50/P95), Fehlerrate, Kosten pro 1.000 Token.
- Release-Strategie: Canary-Releases, A/B-Tests, parallele Modellversionen, harte SLAs für Enterprise.
Anpassung und Personalisierung
- Profile & Policies: Definiere Tonalität, Formalitätsgrad, Domänenprioritäten pro Team/Use-Case.
- Retrieval-Quellen: Binde Wissensbasen, Confluence, SharePoint, Datenbanken über sichere Konnektoren an.
- Feintuning-Optionen: Wähle zwischen klassischem Fine-Tuning und Adapter-Ansätzen (LoRA) – stets mit Datenschutzgarantien.
- Memory: Steuere, was sich das System merkt (präferierte Formate, Terminologien), und wie du es löschen kannst.
Zukunftsperspektiven
- Agentenökosysteme: Spezialisierte Agenten kooperieren, Meta-Orchestrierung delegiert Aufgaben dynamisch.
- Hybride Intelligenz: Verknüpfung neuronaler Modelle mit symbolischer Logik für nachvollziehbare Schlüsse.
- Fortgeschrittene Multimodalität: Tiefere Integration von Tabellen, Diagrammen, Audio/Video.
- Sichere Tool-Nutzung: Fein granulierte Berechtigungen, Sandboxing, menschliche Absegnung für kritische Aktionen.
- Standardisierung: Audits, Benchmarks und Normen für vertrauenswürdige KI setzen sich durch.
Praktische Checkliste: So bewertest du „Duck AI“ oder eine ähnliche Plattform
| Aspekt | Schlüssel-Frage | Woran du es erkennst |
|---|---|---|
| Modellfähigkeiten | Deckt das System deine Kernaufgaben ab (Text, Code, Bild, Zahlen)? | Demos, Benchmarks, Referenzen, Testzugang |
| RAG-Qualität | Wie gut findet und zitiert es relevante Dokumente? | Quellenangaben, Top-k-Precision, Hybrid-Retrieval |
| Sicherheit | Gibt es Schutz gegen Prompt Injection & Datenlecks? | Policy-Filter, DLP, Red-Teaming-Berichte |
| Datenschutz | Erfüllung von DSGVO/Regionvorgaben und Opt-out? | DPA, Datenresidenz, Auditprotokolle |
| Governance | Wie transparent sind Updates und Verantwortlichkeiten? | Changelogs, Versionstags, Eskalationswege |
| Integration | Passt es in deine Toolchain? | APIs, SDKs, Plugins, Single Sign-on |
| Kosten & Skalierung | Sind Betrieb und Lastspitzen planbar? | Autoscaling, Preismodell, Caching, Routing |
Fazit
„Duck AI“ steht als Referenz für eine moderne, modulare KI-Plattform: leistungsfähige Modelle, ergänzt durch Retrieval, Orchestrierung und strenge Sicherheits- und Governance-Mechanismen. Wenn du sie in der Praxis bewertest, zähle nicht nur die Parameter eines LLMs, sondern betrachte das System als Ganzes: Wie sauber ist die Kontextverwaltung? Wie robust sind Policy-Filter? Wie transparent die Versionierung? Und wie sicher der Umgang mit sensiblen Daten? Erst das Zusammenspiel aus Architektur, Prozessen und Kultur – von Monitoring bis Ethik – macht eine KI-Lösung produktionsreif. Mit der hier skizzierten Struktur kannst du Lösungen, die als „Duck AI“ auftreten (oder ähnlich gebaut sind), fundiert einordnen, zielgerichtet einführen und nachhaltig betreiben.
FAQ
Was ist „Duck AI“ genau?
„Duck AI“ ist in diesem Leitfaden eine realistisch konzipierte Referenzplattform für moderne KI-Systeme. Der Name wird in der Praxis teils für unterschiedliche Projekte verwendet. Entscheidend ist die Architektur: LLMs, RAG, Orchestrierung, Sicherheit, Governance und Integrationen.
Ist „Duck AI“ ein konkretes Produkt?
Nicht zwingend. Es kann als Produktname auftreten, steht hier aber als konzeptioneller Rahmen. Prüfe bei jeder konkreten Lösung die offizielle Dokumentation, um Funktionsumfang und Compliance zu verifizieren.
Wie integriert „Duck AI“ externe Wissensquellen?
Über Retrieval-Augmented Generation: Dokumente werden eingebettet, semantisch gefunden und als Kontext in die Antwortgenerierung eingebracht – idealerweise mit Quellenzitaten und Validierungslogik.
Kann ich „Duck AI“ on-premises betreiben?
Ein professionelles Setup bietet Private-Cloud- oder On-Prem-Optionen, inklusive SSO, Rollenrechten, Audit-Logs und strikter Datenresidenz. Achte auf Hardwareanforderungen und Updateprozesse.
Wie sicher ist das System gegen Prompt Injection?
Sicherheit entsteht durch mehrere Schichten: Input-Sanitization, strikte Systemprompts, Tool-Permissions, Output-Moderation und Red-Teaming. Zusätzlich helfen RAG-Filter und Kontextsilos gegen bösartige Einflüsse.
Wie reduziert „Duck AI“ Halluzinationen?
Durch RAG mit hochwertigen Quellen, Pflichtangaben von Belegen, konservative Antwortstrategien bei Unsicherheit, Tool-Nutzung für Fakten/Mathematik und automatisierte Post-Checks.
Eignet sich „Duck AI“ für Entwicklerteams?
Ja. Es unterstützt Code-Vervollständigung, Fehlersuche, Doku-Generierung, testgetriebene Ansätze und die Berücksichtigung interner Bibliotheken. Datenschutz und IP-Schutz bleiben dabei kritisch.
Wie passt „Duck AI“ zur DSGVO?
Wichtig sind DPA, klare Opt-out-Regeln für Trainingsnutzung, Datenresidenz in gewünschten Regionen, Verschlüsselung, pseudonymisierte Logs, Aufbewahrungsfristen und Löschkonzepte.
Welche KPIs sollte ich im Betrieb messen?
Qualität (Korrektheit, Quellenabdeckung), Sicherheit (Toxicity, DLP), Technik (Latenz, Fehlerrate, Kosten/Token) sowie Nutzersignale (Ratings, Eskalationen, Wiederkehrraten).
Unterstützt „Duck AI“ Multimodalität?
Ein ausgereiftes Setup kombiniert Text mit Bild- und ggf. Audioverarbeitung. Prüfe Modellgrenzen, Datenschutz (bei Bild-/Audiomaterial) und spezielle Evaluationsmetriken.
Wie gehe ich mit regulatorischer Unsicherheit um (z. B. EU AI Act)?
Implementiere Frühwarn- und Anpassungsmechanismen: Risiko-Klassifizierung, Dokumentationspflichten, Audit-Trails, Prozessverantwortlichkeiten und regelmäßige Compliance-Reviews.
Wie starte ich pragmatisch?
Beginne mit einem eng umrissenen Use-Case, messe Qualität und Sicherheit, iteriere über RAG-Verbesserungen, Policies und Prompt-Design – und skaliere erst dann in angrenzende Anwendungsfelder.