Generative AI: Grundlagen, Technologien, Anwendungen, Risiken und wie du sie verantwortungsvoll nutzt
Direkt zum Punkt: Du willst wissen, was hinter Generative AI (generativer KI) steckt, wie die wichtigsten Modelle funktionieren, wo die stärksten Einsatzfelder liegen, welche Risiken bestehen und wie du das Ganze sauber in der Praxis umsetzt? Genau das bekommst du hier – strukturiert, sachlich und mit konkreten Empfehlungen.
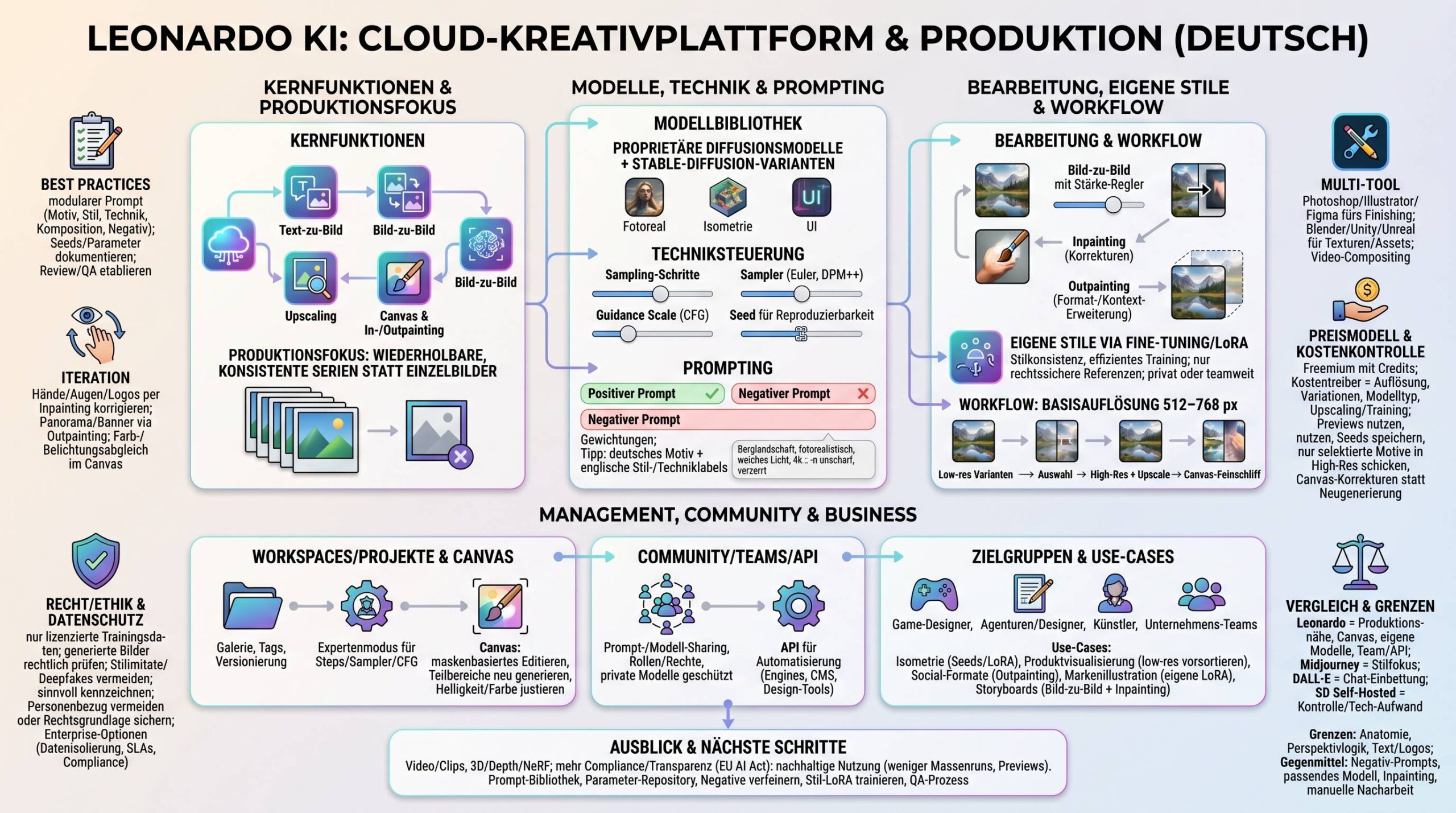
Grundlagen: Was generative KI ausmacht
Generative KI modelliert die Datenverteilung selbst (z. B. p(x) oder bedingt p(x|c)) und erzeugt daraus neue, statistisch konsistente Inhalte. Im Gegensatz dazu lernen diskriminative Modelle primär p(y|x) und treffen Vorhersagen oder Klassifikationen.
Kernidee: Generative KI erzeugt neue Datenpunkte – Texte, Bilder, Audio, Video oder Code – die dem Gelernten ähneln, ohne einfach zu kopieren. Das macht sie zu einer Basistechnologie für Kreativität, Produktivität und digitale Transformation.
Diese Unterscheidung ist praktisch relevant, weil generative Modelle:
- Inhalte synthetisieren (statt nur zu erkennen),
- gezielt konditionierbar sind (z. B. Text-zu-Bild),
- flexibel in zahlreichen Domänen eingesetzt werden können,
- und neue Formen der Kollaboration zwischen Mensch und Maschine ermöglichen.
| Aspekt | Generativ | Diskriminativ |
|---|---|---|
| Ziel | Modellierung von p(x) oder p(x, y); Erzeugung neuer Beispiele | Modellierung von p(y|x); Vorhersage/Entscheidung |
| Beispiele | LLMs, Diffusionsmodelle, VAEs, GANs | Bildklassifikator, Sentiment-Analyse, Spam-Filter |
| Ausgaben | Neue Texte, Bilder, Audio, Code, Videos | Labels, Wahrscheinlichkeiten, Scores |
| Stärken | Flexibel, kreativ, konditionierbar | Effizient, meist präzise auf definierter Aufgabe |
| Grenzen | Faktentreue, Bias, Sicherheit, Missbrauch | Keine Inhaltserzeugung, oft auf Domäne beschränkt |

Kurze Entwicklungslinie
- Frühe Ansätze: Naive Bayes, Hidden-Markov-Modelle, Gaussian Mixtures, Boltzmann-Maschinen – generative Ideen mit begrenzter Praktikabilität.
- 2014–2017: VAEs und GANs leiten die moderne Ära ein; Transformer (2017) revolutionieren Sequenzmodellierung per Self-Attention.
- 2020er: Skalierte LLMs und Diffusionsmodelle liefern Qualitätssprünge in Text, Code, Bild und Audio; Multimodalität gewinnt an Fahrt.
Transformatoren sind heute die prägende Architektur: Sie erlauben es, lange Kontexte effizient zu berücksichtigen und bilden die Grundlage für LLMs, aber auch für Bild-, Audio- und multimodale Modelle.
Wesentliche Modellklassen und Architekturen
Autoregressive Modelle (Text & Code)
Autoregressive Modelle zerlegen Sequenzen in p(x) = ∏ p(x_t | x_{<t}). In der Praxis:
- Training: Teacher Forcing, Kreuzentropie-Verlust.
- Decoding: Greedy, Top-k, Top-p (Nucleus), Temperatursteuerung.
- Stärken: Sprachkompetenz, Kontextsensitivität, universelle Schnittstelle.
- Herausforderungen: Halluzinationen, Fact-Checking, kontrollierte Stiltreue.
Generative Adversarial Networks (GANs)
GANs trainieren Generator und Diskriminator im Minimax-Spiel. Ergebnis: hochrealistische Bilder, aber Training ist anfällig (Instabilität, Modus-Kollaps). Varianten wie WGAN, StyleGAN und BigGAN mildern Probleme und erhöhen die Steuerbarkeit.
Variational Autoencoders (VAEs) & Normalizing Flows
- VAEs: Lernen latente Repräsentationen per ELBO-Optimierung; oft stabiler, aber Bilder teils weicher/unscharfer.
- Flows: Explizite Likelihood über invertierbare Transformationen; kombinieren Sampling und exakte Dichteschätzung.
Diffusions- und Score-based Modelle
Schrittweises Entfernen von Rauschen liefert exzellente Bildqualität und Vielfalt. Stark konditionierbar (Text-zu-Bild), breit einsetzbar in Bild und Audio. Nachteil: Sampling ist iterativ und anfangs rechenintensiv; moderne Verfahren beschleunigen dies.
Multimodale generative Modelle
Kombinieren Text, Bild, Audio, Video in einem System. Typisch: getrennte Encoder, gemeinsamer semantischer Raum, spezialisierte Decoder. Ergebnis: reichhaltige Interaktion (z. B. Bild hochladen, per Text instruieren, visuell oder verbal antworten lassen).
| Modellklasse | Trainingsziel | Stärken | Grenzen | Typische Nutzung |
|---|---|---|---|---|
| Autoregressiv (LLMs) | Nächstes Token vorhersagen | Kontext, Vielseitigkeit, Text/Code | Halluzinationen, Faktentreue | Chat, Schreiben, Programmieren |
| GANs | Adversarial (G vs. D) | Fotorealistische Bilder | Instabil, Modus-Kollaps | Bildsynthese, Stiltransfer |
| VAEs | ELBO (Rekonstruktion + Regularisierung) | Stabil, latenter Raum | Schärfe/Details | Repräsentationslernen, Synthese |
| Normalizing Flows | Exakte Likelihood | Dichte + Sampling | Architekturkomplexität | Anomalieerkennung, Modellierung |
| Diffusionsmodelle | Rauschen entfernen | Qualität, Vielfalt, Konditionierbarkeit | Sampling-Iterationen | Text-zu-Bild/-Audio |
Daten, Infrastruktur und Training
Datensammlung und -aufbereitung
- Quellen: Web, Bücher, Foren, Code-Repos, Bild-Text-Paare, Audio.
- Aufbereitung: Duplikate entfernen, Spam filtern, schädliche Inhalte ausschließen, Sprachen/Kulturen ausbalancieren.
- Recht & Datenschutz: Urheberrecht beachten, personenbezogene Daten minimieren, lokale Rechtslage prüfen.
Praxis-Tipp: Dokumentiere deine Datensätze transparent (Datasheets for Datasets), versieh sie mit Lizenzen und etabliere Opt-out-Mechanismen, wo möglich.
Recheninfrastruktur und Energie
Großmodelle benötigen Cluster aus GPUs/TPUs, Wochen an Trainingszeit und erzeugen signifikanten Energieverbrauch. Effizienzhebel:
- Architektur: sparsames Attention, Low-Rank-Approximationen, Distillation, Quantisierung.
- Betrieb: Mixed Precision, asynchrones Training, Checkpointing, Job-Scheduling.
- Systemisch: Kleine Modelle für Standardfälle, große Modelle nur „on demand“.
Training im Detail (Kurzüberblick)
- LLMs: Pretraining auf großen Korpora, Supervised Finetuning, RLHF (Reinforcement Learning from Human Feedback) zur Ausrichtung an Nutzerpräferenzen.
- Diffusionsmodelle: Vorwärtsrauschen hinzufügen, Rückwärtsnetzwerk trainieren, Sampling mit Steuerung (Guidance) via Text-Encoder.
- GANs: Generator-Diskriminator im Wechsel trainieren; Stabilisierung via Loss-Varianten, Regularisierung, Architekturdesign.

Evaluierung, Robustheit und Sicherheit
Die Bewertung generativer Modelle ist mehrdimensional und domänenspezifisch. Automatische Metriken sind nützlich, korrelieren aber nicht perfekt mit menschlicher Qualitätseinschätzung.
| Domäne | Metrik | Wofür gut | Grenzen |
|---|---|---|---|
| Text | Perplexity | Sprachmodell-Kohärenz | Kein Garant für Nützlichkeit/Fakten |
| Text | BLEU/ROUGE | Ähnlichkeit zu Referenz | Bestraft kreative Paraphrasen |
| Bild | FID, IS | Qualität/Vielfalt vs. echte Daten | Sensitiv auf Datenset/Feature-Extractor |
| Allgemein | Menschliche Bewertung | Nützlichkeit, Angemessenheit, Stil | Kosten, Subjektivität, Reproduzierbarkeit |
Robustheit umfasst Generalisierung (Out-of-Distribution), Resistenz gegen adversarielle Prompts und Stabilität unter realen Nutzungsbedingungen. Sicherheitsmechanismen sind u. a.:
- Inhaltsmoderation (Klassifikatoren, Prompt-Filter, Post-Processing-Regeln)
- Red-Teaming und Sicherheits-Benchmarks
- Retrieval-Augmented Generation (RAG) und Quellenangaben
Anwendungsfelder in der Praxis
Kreativwirtschaft, Design, Medien
- Ideenexploration: Moodboards, Stilvarianten, Konzeptgrafiken innerhalb weniger Sekunden.
- Textproduktion: Entwürfe für Headlines, Teaser, Erzählvarianten; redaktionelle Feinkorrektur bleibt wichtig.
- Produktion: Assets für Games/Film, Bild-zu-Bild-Transformationen, Voiceover-Generierung.
Risiko: Marktübersättigung durch automatisierte Inhalte; offene Fragen zu Urheberrecht und Vergütung kreativer Vorleistungen.
Bildung, Forschung, Wissensarbeit
- Tutor/Coach: Erklärungen, Beispiele, Übungen – personalisiert und adaptiv.
- Materialerstellung: Skripte, Quizfragen, Lernpfade, Zusammenfassungen.
- Forschung: Literaturrecherche, Hypothesenskizzen, Code für Analysen, Datenaugmentierung.
Herausforderung: Akademische Integrität; klare Regeln und didaktische Einbettung sind entscheidend.
Wirtschaft, Marketing, Kundenkommunikation
- Content at Scale: Produktbeschreibungen, E-Mail-Kampagnen, Social-Posts – konsistent, personalisierbar.
- Assistenten/Chatbots: Kontextsensitive Antworten, dynamische FAQs, mehrsprachige Unterstützung.
- Intern: Berichte, Protokolle, Präsentationen und Analysen aus strukturierten Daten generieren.
Beachte: Datenschutz, Markenstimme, Messbarkeit von Conversion und Qualitätssicherung (A/B-Tests, menschlicher Review).
Medizin und Gesundheitswesen
- Dokumentation: Arztbriefe, Befunde, Entlassungsberichte – Zeitersparnis für Fachpersonal.
- Training & Forschung: Synthetische Daten, Simulation pathologischer Befunde, didaktische Visualisierungen.
- Vorsicht: Klinische Entscheidungen erfordern validierte Systeme, klare Aufsicht und Datenschutz.
Industrie, Technik, Simulation
- Generatives Design: Komponentenvarianten unter Material-, Stabilitäts- oder Aerodynamikauflagen.
- Surrogate Models: Näherungen physikalischer Prozesse für schnelle Exploration vor High-Fidelity-Simulation.
- Engineering-Assistenz: Code, Dokumentation, Fehlersuche, Variantenprüfung.
Risiken, Grenzen und Fehlermodi
Halluzinationen und Faktentreue
LLMs erzeugen plausible, aber falsche Inhalte, wenn ihnen gesichertes Wissen fehlt. Gegenmittel:
- RAG: Abruf externen Wissens zur Verankerung von Antworten.
- Transparenz: Unsicherheiten und Quellen angeben.
- Prozess-Prompts: Ketten von Gedankenschritten (Chain-of-Thought), Selbstprüfung.
Bias, Diskriminierung und Repräsentation
Modelle spiegeln Trainingsdaten wider – inklusive Stereotypen und toxischer Inhalte. Maßnahmen:
- Datenkuratierung, Balancierung, Toxizitätsfilter
- Fairness-Analysen und -Benchmarks
- Transparenz über Grenzen und bewusste Nutzungskonzepte
Sicherheit, Missbrauch, Desinformation
Skalierte Text-/Bild-/Audio-Generierung kann für Phishing, Propaganda, Deepfakes missbraucht werden. Gegenmittel:
- Sichere Defaults, Prompt-Blocklisten, Missbrauchsdetektion
- Wasserzeichen/Metadaten zur Herkunftskennzeichnung
- Medienkompetenz, Regulierung, Plattform-Policies
Urheberrecht, Lizenzen und Vergütung
Training auf urheberrechtlich geschützten Werken ist rechtlich und politisch umstritten. Lösungsansätze:
- Opt-out/Opt-in-Mechanismen, klare Lizenzmodelle
- Vergütungssysteme, Kollektivverwertung, Datensatz-Transparenz
- Techniken zum selektiven „Vergessen“ und Nachvollziehbarkeit
Abhängigkeit, Kompetenzverlust, Arbeitsmarkt
Automatisierung kann zu Überabhängigkeit führen und Kompetenzen erodieren lassen, gleichzeitig entstehen neue Rollen (z. B. KI-Moderation, Datencuration). Politische Flankierung und Weiterbildungsangebote sind zentral.
| Risiko | Beschreibung | Gegenmaßnahmen | Hauptverantwortung |
|---|---|---|---|
| Halluzination | Plausible, aber falsche Inhalte | RAG, Quellen, Self-Check | Entwickler, Betreiber, Nutzer |
| Bias | Stereotype/Repräsentationsfehler | Datenkuratierung, Fairness-Tests | Entwickler, Auditoren |
| Missbrauch | Phishing, Desinformation, Deepfakes | Moderation, Wasserzeichen, Policy | Anbieter, Plattformen, Gesetzgeber |
| IP-Konflikte | Urheberrecht, Lizenzen | Transparenz, Vergütung, Opt-out | Anbieter, Rechteinhaber, Regulatoren |
| Kompetenzverlust | Übermäßige Automatisierung | Bildung, Hybrid-Workflows | Organisationen, Bildungssystem |
Governance, Ethik und Regulierung
Responsible-AI-Prinzipien
- Transparenz: Modellbeschreibung, Datenherkunft, Grenzen klar kommunizieren.
- Fairness: Verzerrungen prüfen und mindern.
- Nicht-Schädigung und Sicherheit: Risiken erfassen, mitigieren, überwachen.
- Autonomie & Aufsicht: Mensch in der Kontrolle, Beschwerden/Korrekturen ermöglichen.
- Rechenschaft: Zuständigkeiten, Audits, Dokumentation.
Regulatorische Entwicklungen
Zunehmend setzten Rechtsräume auf risikobasierte Ansätze: höhere Anforderungen an Hochrisikosysteme (u. a. Dokumentation, Datenqualität, Aufsicht, Robustheit). Für generative Systeme werden darüber hinaus Kennzeichnungspflichten, Trainingsdaten-Transparenz und Sicherheitsstandards diskutiert.
Technische Mittel für Nachvollziehbarkeit
- Explainability: Aufmerksamkeitssichten, Attribution, Analyse latenter Repräsentationen.
- Content Provenance: Wasserzeichen, „Content Credentials“, Metadaten-Standards.
Partizipation und globale Gerechtigkeit
Generative KI wird stark von ressourcenstarken Akteuren geprägt. Für inklusive Gestaltung sind offene Forschung, Barriereabbau, Beteiligung marginalisierter Gruppen und internationale Kooperation entscheidend.
Zukünftige Entwicklungen
Von Modellen zu Agenten
Generative Systeme werden zu Agenten, die Ziele verfolgen, Werkzeuge nutzen, planen und Gedächtnis einsetzen. Herausforderung: Kontrollierbarkeit, Robustheit, Sicherheit in offenen Umgebungen.
Faktentreue durch Wissensintegration
Kombination generativer Modelle mit Wissensgraphen, Datenbanken und normativen Textsammlungen. Ziel: Faktenhaltigkeit, Zitationsfähigkeit, Selbstüberprüfung und Unsicherheitskommunikation.
Personalisierung und Adaptivität
Mehr On-Device-Anpassung, Federated Learning und modulare Architekturen. Langfristiges Ziel: persönliche Assistenten, die deinen Kontext kennen und sich kontinuierlich anpassen, ohne katastrophales Vergessen.
Effizienz und Nachhaltigkeit
Effizientere Modelle/Hardware (u. a. spezialisierte Beschleuniger, Komprimierung) und hierarchische Modelllandschaften (Kleinmodelle für Standard, Großmodelle „bei Bedarf“) zur Senkung von Kosten und CO₂-Fußabdruck.
Philosophische und kulturelle Fragen
Autorschaft, Kreativität, ästhetische Vielfalt und Arbeitsverständnis verändern sich. Gesellschaftlicher Diskurs wird wichtiger, je unsichtbarer generative KI in Alltagsprozesse integriert ist.
Praxisleitfaden: So startest du strukturiert
Checkliste für deinen Einstieg
- Problem und Nutzen klären: Welcher Prozess profitiert? Welche Qualität/Speed-Up ist nötig?
- Daten prüfen: Qualität, Rechte, Repräsentation, Datenschutz. Dokumentation erstellen.
- Modellauswahl: LLM vs. Diffusion vs. VAE/Flow/GAN – siehe Tabelle oben.
- Architektur & Tools: RAG, Prompt-Templates, Guardrails, Observability.
- Evaluierung designen: Autometriken + menschliche Bewertung, A/B-Tests, Zielmetriken.
- Governance aufsetzen: Responsible-AI-Policies, Freigaben, Rollenklarheit, Auditlog.
- Pilot & Finetuning: Klein starten, iterieren, Kosten/Nutzen messen.
- Skalierung & Betrieb: Monitoring, Feedback-Schleifen, Red-Teaming, Updates.
Best Practices
- Transparenz gegenüber Nutzenden: Kennzeichne KI-Generierung, zeige Quellen.
- „Human-in-the-Loop“: Kritische Entscheidungen nicht ohne menschliche Freigabe.
- Kontinuierliche Verbesserung: Fehlerkataloge, Drift-Detektion, regelmäßige Re-Tests.
- Datensparsamkeit: Nur nötige Daten verwenden; PII schützen, Policies durchsetzen.
- Messbare Ziele: Definiere klare KPIs (Qualität, Zeit, Zufriedenheit, Conversion, Risiken).
Merke: Generative AI entfaltet ihren Wert, wenn du sie als Werkzeug in robuste Prozesse einbettest – mit klaren Zielen, Leitplanken und verlässlicher Evaluierung.
Fazit
Generative KI ist eine Basistechnologie der Digitalisierung, die Inhalte über Modalitäten hinweg erzeugen und Arbeitsprozesse tiefgreifend verändern kann. Technisch stützt sie sich auf leistungsfähige Architekturen (Transformer, Diffusion, VAEs, GANs, Flows) und riesige Datensätze, operiert aber probabilistisch und bleibt damit fehleranfällig – insbesondere bei Fakten, Fairness und Sicherheit. Für dich in der Praxis zählt deshalb eine balancierte Umsetzung: kluge Problemwahl, solide Daten, geeignete Modell- und Toolauswahl, saubere Evaluierung und eine klare Governance mit menschlicher Aufsicht. Gelingt das, lassen sich Produktivität, Qualität und Innovationsgeschwindigkeit deutlich steigern – ohne die Kontrolle aus der Hand zu geben.
FAQ
Was ist Generative AI – knapp erklärt?
Generative AI (generative KI) sind Modelle, die die Verteilung von Daten lernen und daraus neue Inhalte erzeugen können: Texte, Bilder, Audio, Video oder Code. Im Unterschied zu diskriminativen Modellen klassifizieren sie nicht nur, sondern schaffen Neues.
Worin unterscheidet sich generative von diskriminativer KI?
Generativ: erzeugt Daten (p(x), p(x|c)), z. B. ein neues Bild. Diskriminativ: sagt Klassen/Labels zu vorgegebenen Daten voraus (p(y|x)), z. B. „Katze“ vs. „Hund“.
Wie zuverlässig sind große Sprachmodelle (LLMs)?
LLMs sind sprachlich kompetent, können aber halluzinieren. Nutze Retrieval (RAG), Quellenangaben und menschliche Reviews für kritische Anwendungen.
Welche Modellklasse wähle ich wofür?
Text/Code: autoregressive LLMs. Fotorealistische Bilder: Diffusion oder moderne GANs. Latentes Repräsentationslernen: VAEs. Exakte Dichten/Anomalien: Flows. Multimodalität: kombinierte Encoder/Decoder-Ansätze.
Wie kann ich Halluzinationen reduzieren?
RAG (Wissensabruf), Prozess-Prompts (Chain-of-Thought), Self-Consistency, Quellenangaben und Unsicherheitskommunikation. Zusätzlich domänenspezifische Finetunes.
Ist das Training auf Webdaten rechtlich unbedenklich?
Nein, das ist umstritten und rechtsraumabhängig. Kläre Rechte, setze auf lizenzierte/offene Daten, biete Opt-out, dokumentiere Datenherkunft.
Wie bewerte ich generative Modelle sinnvoll?
Kombiniere Autometriken (Perplexity, BLEU/ROUGE, FID) mit menschlicher Bewertung, A/B-Tests und Domänenkennzahlen (Qualität, Nützlichkeit, Sicherheit).
Welche Risiken muss ich priorisieren?
Faktentreue, Bias/Fairness, Sicherheit/Missbrauch, IP/Urheberrecht, Datenschutz und Kompetenzverlust. Etabliere Governance, Moderationsschichten und Audits.
Wie hoch ist der Energieverbrauch – und was kann ich tun?
Training/Betrieb großer Modelle ist energieintensiv. Nutze effizientere Architekturen, Distillation/Quantisierung, Mixed Precision, Edge-first-Strategien und rufe große Modelle nur „bei Bedarf“.
Wie starte ich praktisch im Unternehmen?
Use Case definieren, Daten prüfen, Modell/Tooling wählen, Evaluierung/Guardrails aufsetzen, Pilot mit „Human-in-the-Loop“, iterieren, skalieren und kontinuierlich überwachen.
Wird Generative AI Arbeitsplätze ersetzen?
Sie automatisiert Teilaufgaben und verändert Rollenprofile. Nettoeffekte hängen von Politik, Weiterbildung und Adoptionsgeschwindigkeit ab. Proaktiv gestalten: Umschulung, neue Verantwortlichkeiten, klare Leitplanken.